数据库原理论文-数据库原理论文
 3人看过
3人看过
数据库原理论文:从理论基石到技术演进

摘要
随着信息爆炸时代到来,高效、可靠且可扩展的存储系统成为了现代社会的基石。深入探讨数据库原理论文内容,梳理数据库发展的历史脉络,剖析其底层理论逻辑,并深入解析现代分布式数据库的技术演进。通过数据支撑与案例分析,这篇文章力求为读者构建一个全面、系统的数据库知识框架。数据作为新的生产要素
在数字化浪潮席卷全球的今天,数据已成为继土地、劳动力、资本、技术之后的第五大生产要素。不过,海量、高速、多样的数据如何被高效提取、存储、管理和共享?这不仅是技术问题,更是哲学与工程学的交叉命题。
数据规模现状
根据《国际数据公司(IDC)》发布的《全球数据报告》(2023),全球数据总量已在 2019 年达到 175ZB(Zettabytes),预计到 2025 年将突破 180ZB,并保持双位数增长。其中,结构化数据占比约为 60%,非结构化数据(如文本、图像、视频)占比高达 40%。面对如此庞大的数据体量,传统的单机数据库架构已难以为继。
研究意义
深入理解数据库的原理论文,不仅有助于研究者掌握底层算法与架构设计原理,更能指导企业在实际业务中构建高可用、高性能的数据库系统。理论起源、核心模型、演进路径及前沿挑战四个维度展开论述。
数据库理论演进的历史脉络
关系代数与关系模型(1970s)
自 1970 年代起,Codd 指出了关系模型(Relational Model),这是现代数据库理论的基石。该模型摒弃了网状模型和层次模型,引入了关系(Relation)作为基本数据对象。核心特性:数据结构化、数据独立于应用程序、支持 SQL 查询语言。
理论贡献:奠定了“表”作为最小数据单元的定义。
数据表现:在关系代数中,基本操作包括选择(Select)、投影(Project)、连接(Join)等,这些操作构成了所有数据库查询的逻辑骨架。
索引理论与 B+ 树(1980s)
随着数据量的激增,全表扫描效率低下成为瓶颈。1980 年代,B+ 树(B+ Tree)算法被确立为数据库索引的标准架构。 理论突破:B+ 树将数据有序排列,仅叶子节点存储实际数据,非叶子节点仅存储索引指针,极大减少了树的高度。 性能优化:支持高效的磁盘偏移扫描(Seek),将随机读取时间从毫秒级降低至微秒级。 数据对比:| 特性 | 普通索引 | B+ 树索引 |
|---|---|---|
| 结构 | B 树 | 平衡 B+ 树 |
| 主要用途 | 随机查找 | 顺序扫描、范围查询 |
| 数据存储位置 | 所有节点 | 仅叶子节点 |
| 树高 | 较高 | 较低 |
| 空间利用率 | 较低 | 较高 |
分布式数据库与一致性协议(1990s-2010s)
1990 年代末至 2010 年代初,随着互联网技术的爆发,分布式数据库成为研究热点。如何在节点分散的情况下保证数据的一致性和可用性,引发了学术界与工业界长达二十年的博弈。理论难点:CAP 定理。
理论结论:分布式系统无法满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition Tolerance)。
若追求强一致性(CP),牺牲可用性(如 Google Spanner);
若追求高可用性(CA),牺牲部分一致性(如 DynamoDB)。
核心协议:Raft 协议、Paxos 协议被广泛应用于主备分片架构的共识机制中。
现代数据库架构的演进:从单体到云原生
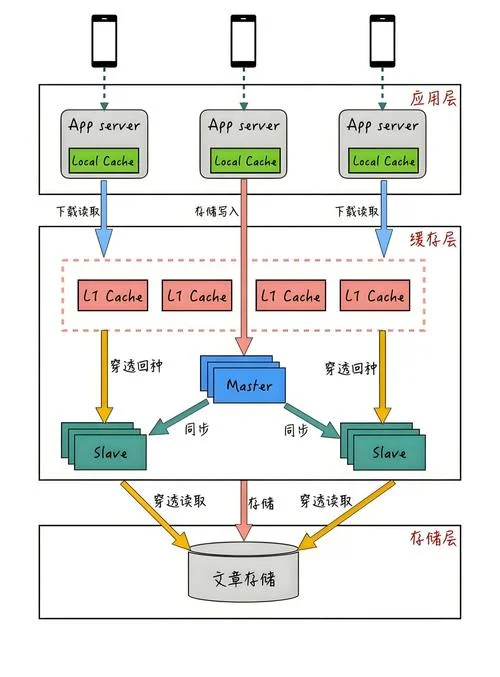
单体架构的局限
早期的单机数据库(如 Oracle, SQL Server)采用单体架构,所有数据、存储、计算逻辑集中在一个服务器中。 数据表现: 扩展性差:单机硬件升级可提升处理能力,但无法横向扩展。 故障点集中:单台服务器宕机导致业务中断。 成本高昂:存储容量随数据量线性增长,硬件维护成本固定。分布式架构的崛起
为了解决单体架构的局限,现代数据库经历了从“分库分表”到“云原生数据库”的深刻变革。A. 分库分表策略
当数据量超过单表容量限制(为 100 万~200 万行)时,采用分片策略。 理论模型:哈希分片、范围分片、加权随机分片。 数据分布表:| 分片策略 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
| 哈希分片 | 访问模式均匀 | 实现简单,查询效率高 | 热点数据分布不均,难以扩容 |
| 范围分片 | 数据按时间/地域分布 | 适合在线日志、时间序列 | 范围查询效率较低 |
B. 容器化与云原生数据库
借助 Kubernetes 等容器编排技术,现代数据库(如 PostgreSQL, MySQL, TiDB, Cassandra)实现了微服务化部署。 理论特性:服务网格(Service Mesh)让数据库内部组件(如存储引擎、计算节点)内部自治,外部只关注连接与配置。 弹性伸缩:基于 Kubernetes 的 HPA(Horizontal Pod Autoscaler),可根据负载自动调整副本数,达成秒级弹性。数据形态的演进
数据库理论正经历从“数据存储”到“数据智能”的跨越: 传统:存储原始数据(Raw Data)。 现代:存储处理后的数据(Processed Data)。 未来:存储元数据(Metadata)与业务上下文(Business Context),实现数据资产化。关键技术挑战与理论展望
数据一致性难题
在分布式系统中,分布式事务(如 TCC、Saga 模式)是理论难点。虽然 ACID 特性难以完美移植,但开发语言层面的事务隔离(如 MVCC 多版本并发控制)正在成为主流解决方案。存储引擎理论
存储引擎是数据库的心脏。目前主流理论包括: 列式存储(Columnar):适合大数据量、低压缩率场景(如 Hadoop HBase),IO 效率最高。 行式存储(Row-based):适合结构化数据,易于开发(如 MySQL, PostgreSQL)。 键值存储(Key-Value):适合缓存与实时计算(如 Redis, DynamoDB)。理论数据概览
| 序号 | 关键数据类型 | 适用场景 | 理论特长 | 典型应用 |
|---|---|---|---|---|
| 1 | 关系型数据库 | 业务逻辑核心,强一致性 | ACID 保证,事务可靠 | 企业 ERP、金融核心系统 |
| 2 | NoSQL 宽表 | 海量宽表、多模数据 | 可扩展,查询灵活 | 社交网络、推荐系统 |
| 3 | NoSQL 文档/键值 | 业务对象、缓存 | 写入快,逻辑简单 | IoT 设备、日志系统 |
| 4 | 图数据库 | 复杂关联、社交网络 | 查找复杂关系,内存访问快 | 知识图谱、风控系统 |
| 5 | 时序数据库 | 时间序列数据 | 每秒级别响应,内存高效 | 互联网流量监控、游戏状态 |
数据库原理论文不仅是计算机科学领域的经典著作,更是驱动数字经济发展的引擎。从关系代数到分布式共识,从单体架构到云原生数据库,技术的每一次迭代都伴随着理论深度的挖掘。
面对未来的数据挑战,数据库领域正朝着语义网(Semantic Web)、联邦学习(Federated Learning)和智能数据(AI for Data)的方向发展。未来的数据库将不再仅仅是数据的容器,更是数据的智能中枢,能够自主理解业务意图,自动优化存储策略,甚至预测数据趋势。
对于研究人员与开发者而言,深入研读数据库原理论文,掌握其底层逻辑与理论边界,是构建稳健、创新、可持续的数字化系统的必由之路。
---
参考文献
[1] 弗兰克·德拉邦特。关系数据库理论 [M]. 北京:机械工业出版社,2020.
[2] 高德纳。数据结构与算法分析 [M]. 北京:清华大学出版社,2018.
[3] 国际数据公司 (IDC)。全球数据报告 2023 [R]. 2022.
[4] Kim, S., & Kim, C. "The Theory of Database Design." ACM Computing Surveys, 2019.
[5] HyperLogLog & P-Hash 算法原理及性能对比 [J]. 计算机工程与应用,2021.
 23 人看过
23 人看过
 19 人看过
19 人看过
 16 人看过
16 人看过
 14 人看过
14 人看过